

Authors: Andrej Čop, Blaž Bertalanič, and Carolina Fortuna
Organization: Jozef Stefan Institute (JSI)
Artificial Intelligence is no longer just in massive data centers. It is moving to the network edge, which includes devices closer to where we work and live. Either your local server, personal computer, or even edge devices such as mobile phones.
The tools for managing AI in these environments are often complex and difficult to use. The process of setting up the necessary frameworks can be a challenge, or if a simple solution exists, it is usually closed source and confined to a vendor or a cloud provider.
As part of the NANCY project, we present NAOMI, an open source MLOps system designed to democratize AI workflows for network systems. Its goal is to make managing the entire life cycle of an AI or ML model straightforward and accessible to a broader audience. We achieved that by connecting existing open source MLOps frameworks into a single modularised system deployed on Kubernetes on-premises or network infrastructure.
What is MLOps?
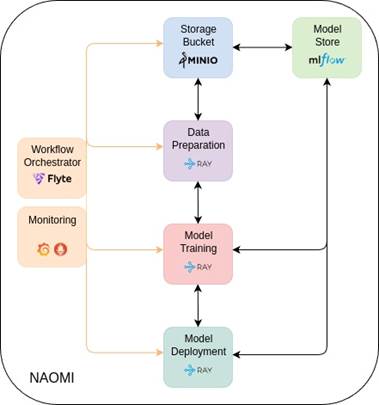
MLOps means Machine Learning Operations, and it aims to automate ML and AI procedures such as data preparation, model training, and model deployment. NAOMI is a complete production MLOps system that helps you manage an entire AI workflow, from start to finish.
While you are probably familiar with building ML models on some Jupyter Notebook or local Python files, eventually those models have to be deployed and used, and later retrained when they are not accurate enough. Or what we call model drift. An AI workflow has several stages, and NAOMI provides the right tools for each one. Here is a look at the system’s architecture and its stages:
- Data Preparation: First, you need to collect and prepare your data. NAOMI uses tools like MinIO as an object store to store the data and a library of choice to handle the pre-processing, while it also provides the Ray Data framework for efficient distributed data processing.
- Model Training: This is where the model learns from the data. NAOMI uses the Ray framework, which lets you train models using popular libraries like TensorFlow or PyTorch distributively on multiple computers.
- Model Store: Once you have a trained model, you need a place to store and version it, similarly to how git manages code versioning, but for ML models. NAOMI uses MLflow for this, so you can keep track of your best models.
- Model Deployment: The model is then made available for inference. Ray Serve handles this by creating a simple API access point for your model on your cluster IP.
- Orchestration: To automate the entire process and define the workflow, NAOMI uses Flyte as its workflow orchestrator. Flyte containerises the separate tasks and enables automation.
- Monitoring: To make sure that everything is working as expected, NAOMI uses Prometheus and Grafana to report metrics about the system and its components.
This results in a direct acyclic graph which defines an AI workflow of all the tasks and how they interconnect:
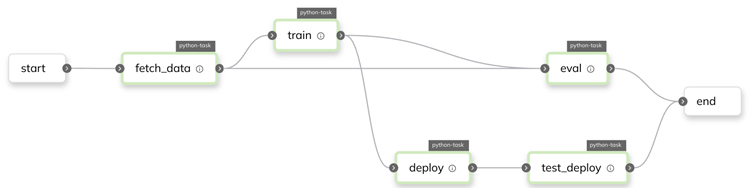
For example, in this figure, we can see the dependencies between tasks such as data fetching and training.
What are the benefits?
NAOMI was built on several key principles to ensure it is accessible and useful.
It’s Easy to Get Started: One of the main principles we were following while developing NAOMI is ease of use. A so-called democratized solution. NAOMI can be deployed on your own infrastructure in just a few steps.
Adjust to Your Own Needs: NAOMI is completely modular. If you only need one part of the system, like the model store, you can disable the rest to save resources. This allows you to interchange components with minimal engineering effort to suit your specific use case. You can also use each part of the system individually.
Runs on Various Hardware: Edge devices vary in their architecture. NAOMI was designed to support this heterogeneity. It can be deployed on a distributed cluster of standard x86 computers and ARM devices, like the Raspberry Pi. This allows you to utilize the existing infrastructure and enables features like model deployment on the network edge, closer to users, and therefore reduces latency.
NAOMI is Self-Evolving: A model’s performance can degrade over time as conditions change. NAOMI is meant as a self-evolving system, meaning it supports workflows that automatically manage and retrain models. It supports collecting metrics about the model and using automated triggers to retrain and redeploy models, ensuring they remain effective without manual intervention.
Try It Yourself
NAOMI is open source and available for anyone to use. You can get started by visiting the NAOMI GitHub repository. The repository includes documentation, setup scripts, and four different example workflows to help you learn the system.
- Get the code: You can find the entire project at https://github.com/sensorlab/NAOMI.
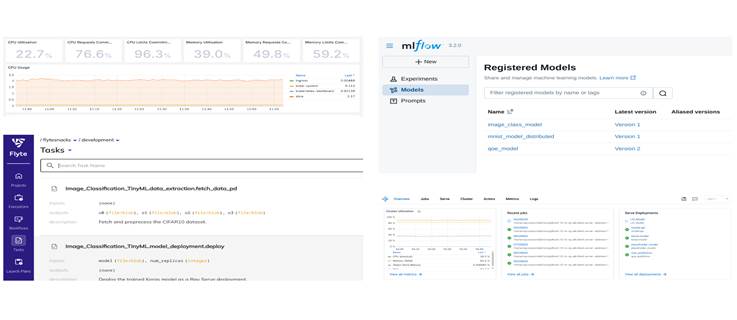
- Run an example: The repository provides instructions to deploy the system and see it in action on our examples. The dashboards of NAOMI will look like the figure below.
- Read the research paper: For a deep dive into the architecture and evaluation of related work, you can read the full scientific paper. https://www.sciencedirect.com/science/article/pii/S1084804525000773
Conclusion
In this blog, we showed that NAOMI provides a modular and architecture-independent solution for managing AI workflows at the network edge. By focusing on ease of use, it lowers the barrier for anyone to deploy and use such a system for their own AI use case.
